The goddess of wisdom giggles with glee as Cupid's foot stomps on Jay's sons
2020-11-07
Here’s a sad tale of a bozo defeated hacker giving up on json_extract() going 6+ levels deep.
As part of our “making someone care about their cloud” we had some pretty complicated json to hack and slash and put into reports. We took copies from our probes and secureatai hub backup rig and split it into something Athena can query, group by and join and Quicksight can draw dashboards for.
Being a rhetorical recursive strange loop myself - it came naturally to want to dumb everything down to what my alcohol wracked brain can grasp - single depth paquet files.
So I slapped a stasher, stomper and some housekeeping into a picture that goes something like this…
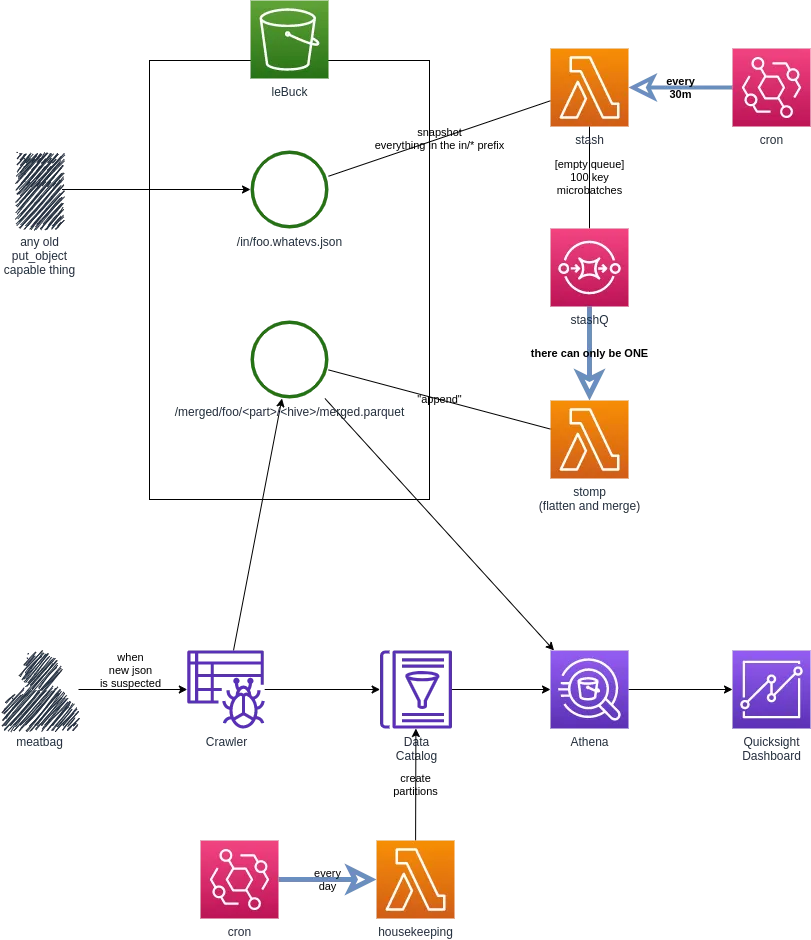
The process starts with something put_object’ing some json into the in/ prefix. Every 30 minutes, the stasher takes a snapshot of everything in in/ and dumps messages containing 100 keys on an SQS queue.
The stomper being wired to the queue processes those 100 key messages one at a time and ‘appends’ them to the merged/ prefix.
Once a day the housekeeping welcomes in the new day by adding new partitions to the tables.
The stasher
import boto3
import os
import math, random, re
import json
sqs = boto3.client('sqs', region_name='eu-west-1')
s3 = boto3.client('s3', region_name='eu-west-1')
leQ = os.environ['SQS']
leMaxO = int(os.environ['MAXO'])
leBuck = os.environ['S3_BUCKET']
lePrefix = os.environ['PREFIX']
datere = re.compile('(\d{4})-(\d{2})-(\d{2})')
def get_hive_path(tests):
for t in tests:
m = datere.match(t)
if m:
(y,m,d) = m.groups()
break
timepath = 'year='+y+'/month='+m+'/day='+d
return timepath
def handler(event, context):
qresp = sqs.get_queue_attributes(
QueueUrl=leQ,
AttributeNames=['All'])
if qresp['Attributes']['ApproximateNumberOfMessages']!='0':
print ('queue not empty, returning',qresp['Attributes']['ApproximateNumberOfMessages'])
return
paginator = s3.get_paginator('list_objects_v2')
operation_parameters = {
'Bucket': leBuck,
'Prefix': lePrefix
}
page_iterator = paginator.paginate(**operation_parameters)
merge_buff = []
total = 0
msg_count=0
for page in page_iterator:
for i in page['Contents']:
key = i['Key']
hivepath = get_hive_path([key,str(i['LastModified'])])
group = os.path.split(key)[1].split('.')[0]
merge_buff.append( {
'key': key,
'hivepath': hivepath,
'group': group
})
if len(merge_buff)>=leMaxO:
msg_count=msg_count+1
sqs.send_message(
QueueUrl=leQ,
MessageBody=json.dumps(merge_buff),
MessageGroupId='str(math.floor(random.random()*3))'
)
merge_buff.clear()
total=total+1
if len(merge_buff) > 0:
msg_count=msg_count+1
sqs.send_message(
QueueUrl=leQ,
MessageBody=json.dumps(merge_buff),
MessageGroupId='str(math.floor(random.random()*3))'
)
print ('msgs', msg_count, 'records',total)
So the stasher checks if there are any messages in the queue and if it is empty, it takes a snapshot of everything in the in/ prefix and sends them in leMaxO (100) groups into the queue.
Maybe note the MessageGroupId as a string to only have ONE consumer at a time.
If it weren’t for that, multiple stompings would happen and the same time and data will be lost, which is badong…
The stomper

The flattening function script (ffs) is nothing but a bunch of recursion hacked into python class that spits out the flattened json parts.
import uuid
class Flattener:
def __init__(self,leobj):
self.flatties = {}
self.tgroups = {}
self.leobj = leobj
def flatten(self):
flatties = self.flatties
def get_name(parent,col):
return parent.split('.')[-1]+'.'+col
def process(parent_id, name, obj):
if type(obj) == list:
my_id = parent_id
if len(obj) > 0 and type(obj[0]) != dict and type(obj[0]) != list: #if a dumbass list
for val in obj:
my_id = str(uuid.uuid4())
flatties[my_id]={ 'parent_id': parent_id, 'obj_id': my_id,
'name': name, 'values': [{name:val}]}
else:
for i in obj:
process(my_id, name,i)
elif type(obj) == dict:
my_id = str(uuid.uuid4())
flatties[my_id]={ 'parent_id': parent_id, 'obj_id': my_id, 'name': name, 'values': []}
for i in obj:
newName = get_name(name,i)
process(my_id, newName ,obj[i])
else:
flatties[parent_id]['values'].append({name:obj})
process('0', 'root',self.leobj)
self.make_tgroups()
return self.make_parts()
def make_tgroups(self):
flatties = self.flatties
tgroups = self.tgroups
for i in flatties:
name = flatties[i]['name']
if name in tgroups:
tgroups[name].append(flatties[i])
else:
tgroups[name] = [flatties[i]]
def make_parts(self):
tgroups = self.tgroups
parts = {}
for t in tgroups.keys():
parts[t] = []
for row_obj in tgroups[t]:
for col in row_obj['values']:
row_obj.update(col)
row_obj.pop('values')
row_obj.pop('name')
parts[t].append(row_obj)
return parts
The main flatten method wraps the recursive process and ends off by make_tgroups grouping the json parts and make_parts putting the bits into part ‘tables’.
The get_name function only takes the last parent’s name, but if you remove the [-1] you should see the whole tree (it goes loony if your property names are long and your nesting is deep).
and the merging handler that goes with it
import sys
sys.path.insert(0,'lib')
import os, io
import boto3, json
from foot import Flattener
import pandas as pd
import threading
import botocore
leBuck = os.environ['S3_BUCKET']
s3 = boto3.client('s3', config=botocore.client.Config(max_pool_connections=100))
ignoreList = json.loads(os.environ['IGNOREPATHS'])
def download(leFile):
try:
resp = s3.get_object(Bucket=leBuck,Key=leFile['key'])
leFile['contents']=resp['Body'].read()
except Exception as e:
print (leFile['key'], 'could not find key',e)
def upload(leFile):
s3.put_object(Bucket=leBuck,Key=leFile['key'],Body=leFile['contents'])
def whack(leFile):
s3.delete_object(Bucket=leBuck,Key=leFile['key'])
def thread_do(func, kList):
leThreads = []
for k in kList:
leThreads.append(threading.Thread(target=func, args=([k])))
for leThread in leThreads:
leThread.start()
for leThread in leThreads:
leThread.join()
def handler(event, context):
merge_buff = json.loads(event['Records'][0]['body'])
merged_parts = {}
thread_do(download, merge_buff)
print ('downloaded jsons',len(merge_buff))
for c,i in enumerate(merge_buff):
jsono = json.loads(i['contents'])
flattie = Flattener(jsono)
parts = flattie.flatten()
dlist = []
for partname in parts.keys():
ppname = i['group']+'/'+partname+'/'+i['hivepath']
if ppname not in merged_parts:
dlist.append({'key': 'merged/'+ppname+'/merged.parquet', 'pname': ppname})
if len(dlist) > 0:
thread_do(download, dlist)
for d in dlist:
merged_parts[d['pname']] = { 'key': d['key'] }
if 'contents' in d:
merged_parts[d['pname']]['df'] = pd.read_parquet(io.BytesIO(d['contents']))
else:
merged_parts[d['pname']]['df'] = pd.DataFrame()
for partname in parts.keys():
ppname = i['group']+'/'+partname+'/'+i['hivepath']+''
df = pd.DataFrame(parts[partname])
for col in df.iteritems(): #make int-erica json-reat again
cname = col[0]
if 'int' in str(df[cname].dtype):
df[cname]=df[cname].astype(float)
merged_parts[ppname]['df']=pd.concat([merged_parts[ppname]['df'],df])
print ('stomped',len(merge_buff))
ulist = []
for ppname in merged_parts.keys():
bf = io.BytesIO()
merged_parts[ppname]['df'].to_parquet(path=bf, compression="gzip", index=False, partition_cols=None)
bf.seek(0)
bbuf = bf.read()
ulist.append({'key':merged_parts[ppname]['key'], 'contents': bbuf})
thread_do(upload, ulist)
print ('saved merged',len(merged_parts.keys()))
thread_do(whack, merge_buff)
print ('cleaned up src',len(merge_buff))
the handler (trying to multi-thread all the s3 io):
- downloads the json files
- for each file flattens them into parts
- downloads the already merged parquet files
- and appends the file’s parts to the merged_parts, keeping it around just in case they are needed again
- once done uploads all the merged parts to the
merged/prefix - whacks the
in/key
to illustrate the process and the scale of our problem (mostly caused by 101 accounts triggering sechub findings during the day)
If you give it a json file like this
[
{
"_id": "5f798a9472abeace01a3360e",
"index": 0,
"guid": "5f26bde8-d424-4747-bb51-ede261fcfa3a",
"isActive": true,
"balance": "$3,916.90",
"picture": "http://placehold.it/32x32",
"age": 32,
"eyeColor": "blue",
"name": { "first": "Kendra", "last": "Norton" },
"company": "FIBEROX",
"email": "kendra.norton@fiberox.biz",
"phone": "+1 (913) 519-3463",
"address": "160 Dahill Road, Vienna, Oregon, 8471",
"about": "Proident irure esse cillum ad cupidatat ea ut cupidatat amet ex Lorem in qui. Consequat tempor eu nostrud aliqua aliquip velit aute sunt fugiat ipsum tempor. Et laboris ipsum laborum nostrud cillum exercitation exercitation. Non ullamco minim qui laboris duis non nostrud anim eu ipsum anim culpa. Enim eu in ex irure magna veniam minim. Reprehenderit fugiat mollit nisi officia nostrud minim labore cillum elit ullamco. Cupidatat non culpa ea dolore sunt fugiat dolore ut sint elit ex.",
"registered": "Thursday, April 7, 2016 2:23 AM",
"latitude": "-55.561312",
"longitude": "-71.118604",
"tags": [ "commodo", "eu", "esse", "cupidatat", "duis" ],
"range": [ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 ],
"friends": [ {
"id": 0,
"name": "Mollie Abbott",
"feelings" : [ "light", "noice" ]
},
{
"id": 1,
"name": "Dixon Swanson",
"feelings" : [ "heavy", "noice" ]
},
{
"id": 2,
"name": "Bowman Mills",
"feelings" : [ "heavy", "annoying" ]
}
],
"greeting": "Hello, Kendra! You have 10 unread messages.",
"favoriteFruit": "apple"
},
{
"_id": "5f798a94c6993ed10a3e4cee",
"index": 1,
"guid": "f73b30b3-3097-4024-8734-3d77e427239a",
"isActive": true,
"balance": "$1,549.09",
"picture": "http://placehold.it/32x32",
"age": 40,
"eyeColor": "brown",
"name": { "first": "Autumn", "last": "Marquez" },
"company": "GOKO",
"email": "autumn.marquez@goko.net",
"phone": "+1 (918) 591-2549",
"address": "712 Bristol Street, Bayview, Oklahoma, 9795",
"about": "Magna ex eu sunt consectetur amet pariatur est culpa exercitation do irure et quis culpa. Cillum occaecat cillum eu amet elit adipisicing sint. Eu aute consectetur Lorem non magna aliquip nostrud nostrud ex esse. Quis nostrud duis commodo excepteur aliquip. Labore pariatur non consequat veniam est voluptate ullamco eiusmod magna occaecat pariatur est ut ex.",
"registered": "Monday, March 3, 2014 8:37 PM",
"latitude": "82.395565",
"longitude": "-99.539596",
"tags": [ "ipsum", "elit", "in", "nulla", "duis" ],
"range": [ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 ],
"friends": [ {
"id": 0,
"name": "Angel Rose",
"feelings" : [ "whoot", "noice" ]
},
{
"id": 1,
"name": "Lorie Castillo",
"feelings" : [ "noice" ]
},
{
"id": 2,
"name": "Rodriquez Wiggins",
"feelings" : [ "heavy", "noice", "yadda" ]
}
],
"greeting": "Hello, Autumn! You have 9 unread messages.",
"favoriteFruit": "strawberry"
},
{
"_id": "5f798a94d618e03e56545285",
"index": 2,
"guid": "c2739b3f-c2a7-4927-9542-79292386b08d",
"isActive": false,
"balance": "$2,289.16",
"picture": "http://placehold.it/32x32",
"age": 35,
"eyeColor": "green",
"name": { "first": "Stark", "last": "Mccormick" },
"company": "CORIANDER",
"email": "stark.mccormick@coriander.tv",
"phone": "+1 (949) 446-3768",
"address": "601 Homecrest Avenue, Herald, Maine, 2725",
"about": "Magna occaecat aliquip minim commodo deserunt Lorem est. Fugiat non esse reprehenderit veniam ex culpa anim laboris dolore eiusmod enim ad. In nisi officia cillum aliquip ipsum pariatur officia ut. Voluptate fugiat nostrud excepteur anim occaecat labore esse id consequat. Commodo cupidatat ut enim occaecat cillum est laborum quis non. Fugiat et culpa nulla aliqua magna do adipisicing.",
"registered": "Tuesday, October 24, 2017 12:22 AM",
"latitude": "-87.501116",
"longitude": "76.887163",
"tags": [ "cupidatat", "officia", "adipisicing", "mollit", "eiusmod" ],
"range": [ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 ],
"friends": [
{
"id": 0,
"name": "Loretta Thornton",
"feelings" : [ "noice" ]
},
{
"id": 1,
"name": "Hammond Oneal",
"feelings" : [ "heavy", "noice", "high maintenance" ]
},
{
"id": 2,
"name": "Horton Duran",
"feelings" : [ "fluddy" ]
}
],
"greeting": "Hello, Stark! You have 5 unread messages.",
"favoriteFruit": "banana"
}
]
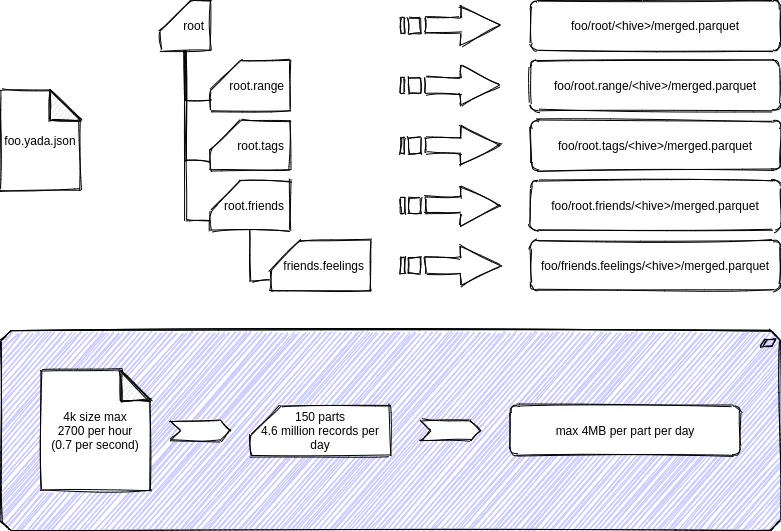
and dump it as in/foo.440a98ab-68af-4548-a349-aa933545f5ee.json you would get something that looks like this in the bucket
2020-10-11 10:30:14 3572 merged/foo/friends.feelings/year=2020/month=10/day=05/merged.parquet
2020-10-11 10:30:14 4626 merged/foo/root.friends/year=2020/month=10/day=02/merged.parquet
2020-10-11 10:30:14 4046 merged/foo/root.friends/year=2020/month=10/day=05/merged.parquet
2020-10-11 10:30:15 3670 merged/foo/root.name/year=2020/month=10/day=05/merged.parquet
2020-10-11 10:30:15 3714 merged/foo/root.range/year=2020/month=10/day=05/merged.parquet
2020-10-11 10:30:15 3354 merged/foo/root.tags/year=2020/month=10/day=05/merged.parquet
2020-10-11 10:30:14 18761 merged/foo/root/year=2020/month=10/day=05/merged.parquet
Starting with the root of the json file, the parquet files that get created looks like this…
---
root:
head: |
- parent_id obj_id root._id root.index root.guid root.isActive ... root.longitude root.greeting root.favoriteFruit year month day
0 0 9c8d4727-8e54-4d04-a36d-cad95c82bef9 5f798a9472abeace01a3360e 0 5f26bde8-d424-4747-bb51-ede261fcfa3a True ... -71.118604 Hello, Kendra! You have 10 unread messages. apple 2020 10 5
1 0 31b1ce05-246f-450f-b523-c67c09ced333 5f798a94c6993ed10a3e4cee 1 f73b30b3-3097-4024-8734-3d77e427239a True ... -99.539596 Hello, Autumn! You have 9 unread messages. strawberry 2020 10 5
2 0 cf9e9799-80ed-4277-aff9-c20345d7ee2e 5f798a94d618e03e56545285 2 c2739b3f-c2a7-4927-9542-79292386b08d False ... 76.887163 Hello, Stark! You have 5 unread messages. banana 2020 10 5
[3 rows x 23 columns]
root.name:
head: |
- parent_id obj_id name.first name.last year month day
0 9c8d4727-8e54-4d04-a36d-cad95c82bef9 a6041dd0-6b80-49bc-918f-849324a5f3f6 Kendra Norton 2020 10 5
1 31b1ce05-246f-450f-b523-c67c09ced333 d0517bd3-4370-4f70-931a-1d4dd9e874a2 Autumn Marquez 2020 10 5
2 cf9e9799-80ed-4277-aff9-c20345d7ee2e eff754ed-20ac-4eb3-a5d1-f51464eb8775 Stark Mccormick 2020 10 5
root.tags:
head: |
- parent_id obj_id root.tags year month day
0 9c8d4727-8e54-4d04-a36d-cad95c82bef9 e37a979d-03b9-439a-af61-6821a9bc7f3f commodo 2020 10 5
1 9c8d4727-8e54-4d04-a36d-cad95c82bef9 f78fc402-d6c5-42f4-a1f0-a03e2bba54fe eu 2020 10 5
2 9c8d4727-8e54-4d04-a36d-cad95c82bef9 fef05eb7-a204-449d-97c3-a831a3234ed4 esse 2020 10 5
3 9c8d4727-8e54-4d04-a36d-cad95c82bef9 014069e5-3ec7-4835-89b8-649db94b7d29 cupidatat 2020 10 5
4 9c8d4727-8e54-4d04-a36d-cad95c82bef9 bd1bc15b-d974-4d6c-8ce1-79924943bfe6 duis 2020 10 5
root.range:
head: |
- parent_id obj_id root.range year month day
0 9c8d4727-8e54-4d04-a36d-cad95c82bef9 25c703aa-5518-41b2-b978-6b00a7e78785 0 2020 10 5
1 9c8d4727-8e54-4d04-a36d-cad95c82bef9 acc1b1a4-9752-4ea1-99a0-1f4f4a65b8e2 1 2020 10 5
2 9c8d4727-8e54-4d04-a36d-cad95c82bef9 d9574b3f-f2de-49be-8a54-b68c01728694 2 2020 10 5
3 9c8d4727-8e54-4d04-a36d-cad95c82bef9 cf42c550-aa13-4d58-9d44-5af5592be46b 3 2020 10 5
4 9c8d4727-8e54-4d04-a36d-cad95c82bef9 8c584f6a-4e81-476e-9a69-b48e805d20ea 4 2020 10 5
root.friends:
head: |
- parent_id obj_id friends.id friends.name year month day
0 9c8d4727-8e54-4d04-a36d-cad95c82bef9 88aee354-1177-4f72-ba44-d6c94e9f529c 0 Mollie Abbott 2020 10 5
1 9c8d4727-8e54-4d04-a36d-cad95c82bef9 f7aa2550-0e02-4bf8-b187-e411b6796d59 1 Dixon Swanson 2020 10 5
2 9c8d4727-8e54-4d04-a36d-cad95c82bef9 17faf155-62c4-4942-8b93-5654abe1c9c5 2 Bowman Mills 2020 10 5
3 31b1ce05-246f-450f-b523-c67c09ced333 22fc1450-7eaa-4502-955c-c0fc6048f072 0 Angel Rose 2020 10 5
4 31b1ce05-246f-450f-b523-c67c09ced333 978e1754-dcaf-4bb3-9902-f002e5d59476 1 Lorie Castillo 2020 10 5
friends.feelings:
head: |
- parent_id obj_id friends.feelings year month day
0 88aee354-1177-4f72-ba44-d6c94e9f529c b0fb58d1-5a2c-4491-bf66-aafb4d4d07c5 light 2020 10 5
1 88aee354-1177-4f72-ba44-d6c94e9f529c f109e06f-8cca-46c9-b49b-a96314ae46ce noice 2020 10 5
2 f7aa2550-0e02-4bf8-b187-e411b6796d59 9d1c8631-ab1f-4582-af04-a70e3cce2b6b heavy 2020 10 5
3 f7aa2550-0e02-4bf8-b187-e411b6796d59 af5fd05d-6474-4f7a-b2f7-f32977f0e3dc noice 2020 10 5
4 17faf155-62c4-4942-8b93-5654abe1c9c5 fb48b967-dfed-4c0f-ad79-125f3e7c74ab heavy 2020 10 5
and then you can start a table join party with <parent table>.obj_id = <child table>.parent_id and with their children’s chilrden etc etc.
** A lamb, a panda and a python walks into an availability zone…**
“Goddammit Panda, did you have to eat that extra helping of doughnuts?” asks Python as he tries to hoist Panda on Lambs back. “Maybe if you just sucked in your tummy a little and I strap these bionic leg braces to Lamb, I could make this work”
Initially, when I prototyped this for shits and giggles, pyarrow was so phat ass I could not make it fit in the 250MB limit, and I had to go for fastparquet. However, when got to hacking recently pandas and pyarrow squeezed in and I managed to make the foot stomp out parquet files.
so the requirements.txt looks like this
pyarrow
pandas
”Housekeeping! Do you want turndown service?”
Copy and pasta of o.great.goog.match[5] begets:
import os
import boto3
import datetime
leDbName = os.environ['DBNAME']
glue = boto3.client('glue', region_name='eu-west-1')
def handler(event, context):
paginator = glue.get_paginator('get_tables')
operation_parameters = {
'DatabaseName': leDbName,
}
page_iterator = paginator.paginate(**operation_parameters)
leDate = datetime.date.today()
for page in page_iterator:
for i in page['TableList']:
print(i['Name'])
glue.create_partition(
DatabaseName=leDbName,
TableName=i['Name'],
PartitionInput={
'Values': leDate.isoformat().split('-'),
'StorageDescriptor': {
'Location': i['StorageDescriptor']['Location']+leDate.strftime('year=%Y/month=%m/day=%d/'),
'InputFormat': i['StorageDescriptor']['InputFormat'],
'OutputFormat': i['StorageDescriptor']['OutputFormat'],
'SerdeInfo': i['StorageDescriptor']['SerdeInfo'],
}
}
)
The seedy-m-kay intravenous delivery
the structure
▾ bin/
flattener.js
▸ cdk.out/
▸ docs/
▾ handlers/
▾ housekeeping/
itisanewday.py
▾ stashie/
stash.py
▾ stompie/
▸ __pycache__/
▸ lib/
foot.py
requirements.txt
stomp.py
▾ lib/
flattener-stack.js
▸ node_modules/
▸ test/
cdk.json
package-lock.json
package.json
the stack
const cdk = require('@aws-cdk/core')
const s3 = require('@aws-cdk/aws-s3')
const iam = require('@aws-cdk/aws-iam')
const sqs = require('@aws-cdk/aws-sqs')
const lambda = require('@aws-cdk/aws-lambda')
const lambdaEventSources = require('@aws-cdk/aws-lambda-event-sources')
const events = require('@aws-cdk/aws-events')
const targets = require('@aws-cdk/aws-events-targets')
class FlattenerStack extends cdk.Stack {
constructor(scope, id, props) {
super(scope, id, props);
const leBuck = new s3.Bucket(this, 'reporting-bucket', {
encryption: "S3MANAGED"
})
const polStatement = new iam.PolicyStatement({
resources: [leBuck.bucketArn+'/*'],
actions: [
"s3:PutObject",
],
principals: [new iam.AccountPrincipal(props.rootAccount)]
})
leBuck.addToResourcePolicy(polStatement)
const leQ = new sqs.Queue(this, 'FlattenQ', {
fifo: true,
contentBasedDeduplication: true,
visibilityTimeout: cdk.Duration.seconds(301)
})
const stashFunc = new lambda.Function(this, 'stashFunc', {
runtime: lambda.Runtime.PYTHON_3_8,
handler: 'stash.handler',
code: lambda.Code.asset('./handlers/stashie'),
timeout: cdk.Duration.seconds(100),
environment: {
SQS: leQ.queueUrl,
S3_BUCKET: leBuck.bucketName,
MAXO: '100',
PREFIX: 'in/'
},
memorySize: 1024,
})
leQ.grantSendMessages(stashFunc)
leQ.grantConsumeMessages(stashFunc)
leBuck.grantRead(stashFunc)
const leRule = new events.Rule(this, 'stashScheduledRule', {
schedule: events.Schedule.expression('cron(*/30 * ? * * *)')
});
leRule.addTarget(new targets.LambdaFunction(stashFunc));
const stompFunc = new lambda.Function(this, 'stompFunc', {
runtime: lambda.Runtime.PYTHON_3_8,
handler: 'stomp.handler',
code: lambda.Code.asset('./handlers/stompie'),
timeout: cdk.Duration.seconds(300),
environment: {
S3_BUCKET: leBuck.bucketName,
IGNOREPATHS: '["probe/msg.Messages"]'
},
memorySize: 2048,
})
stompFunc.addEventSource(
new lambdaEventSources.SqsEventSource(
leQ, { batchSize: 1 }
))
leBuck.grantReadWrite(stompFunc);
const houseFunc = new lambda.Function(this, 'houseFunc', {
runtime: lambda.Runtime.PYTHON_3_8,
handler: 'itisanewday.handler',
code: lambda.Code.asset('./handlers/housekeeping'),
timeout: cdk.Duration.seconds(100),
environment: {
DBNAME: 'reporting',
},
memorySize: 1024,
})
const polHouseStatement = new iam.PolicyStatement({
resources: ['*'],
actions: [
"glue:GetTables",
"glue:CreatePartition",
],
})
houseFunc.addToRolePolicy(polHouseStatement)
const leHouseRule = new events.Rule(this, 'houseScheduledRule', {
schedule: events.Schedule.expression('cron(0 1 ? * * *)')
});
leHouseRule.addTarget(new targets.LambdaFunction(houseFunc));
}
}
module.exports = { FlattenerStack }
See how it runs
So hell, it feels like I spent half of my ‘I can still remember it was somewhere in the last month or two’ time on tweaking this bastard with various alternative implementations - which I will talk about in another post.
Here is a simple grab of what cloud watch’s log insights and spunky new Lambda Insights sees over the course of a day.
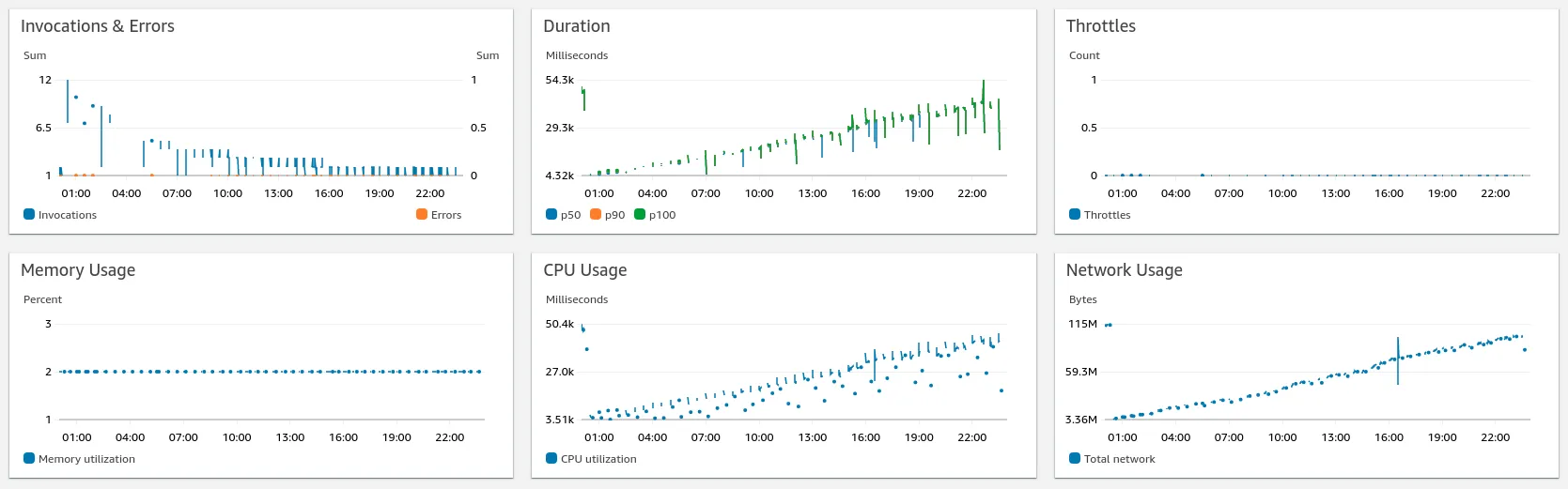
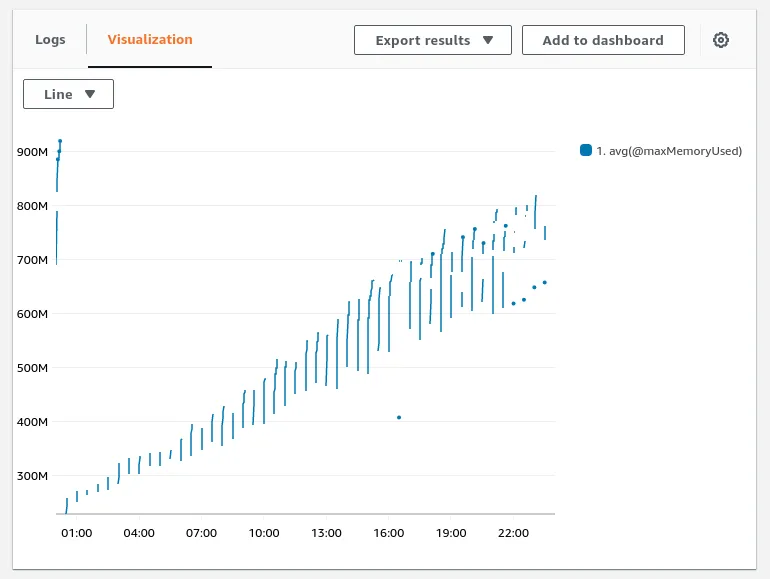
As you can see daily, it starts small and fast and, as the sun moves around the flat earth, it ratchets up more time, memory, cpu and network due to the growing of the merged parquet files.
Anyhoos
- Obviously mileage will vary, and you might want to opt for a glue Rationalize, tweak the memory or turn the recursion into something a little less memory heavy (cache with elastic cache perhaps). But for my simple ‘take api results and make them into tables’ - it works just mkay.