Let the lambs run free in your hosed flow logs
2020-02-22
Our landing zone rig has been diligently stashing network traffic since the beginning of network time (Sept 2017 to be exact).
We were hoping people would come to their senses and ditch the windows but, since all the people and mice didn’t get the ‘no-click’ memo, we recently had to treasure hunt for yet another F-ing Monero#432421.v2
Our vpc and security account automation bits and bobs makes sure the vpc flow logs gets fire hosed into a central account and, since the hose’s dope aint something Athena (or I for that matter) understand fully, we had to set the lambs a grazing on the logs.
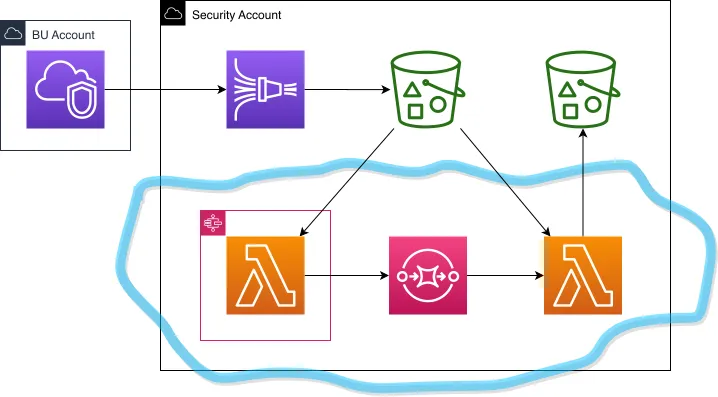 { width=1080 }
{ width=1080 }
Basic gist (circled in blue) is:
-
In a step function, lambda:
- Get the source keys in S3
- Pop them on a queue
- Wait for the queue to drain
-
In a sidecar lambda poked by SQS:
- Stream the weird gzipped thing from S3
- Gunzip
- Regex like it’s 1999
- Gzip
- Stream the resulting csv.gz to S3
The key finder
So the monster Promise.all is not infinitely scalable, as I found out when I tried to sqs.sendMessage 6k promises.
However, using sqs.sendMessageBatch makes things an order of 10 more manageable.
const AWS = require('aws-sdk');
const s3 = new AWS.S3();
const sqs = new AWS.SQS();
const process = require('process');
exports.startBatch = async (event) => {
console.log('starting....',event)
let prefix = event.prefix ? event.prefix : 'firehose2020/02/18/06/'
let leBucket = process.env.S3_BUCKET
let leq = process.env.QUEUE_URL
await sqs.purgeQueue( {
QueueUrl: leq
}).promise()
let keys = []
let cToken = null
let continueWhile = true
let res = await s3.listObjectsV2({ Bucket: leBucket, Prefix: prefix, ContinuationToken: cToken }).promise()
while ( res.Contents.length>0 && continueWhile ) {
cToken = res.NextContinuationToken
console.log(res.Contents.length,cToken)
keys = keys.concat(res.Contents.map(x => {
return {
Bucket: leBucket,
Key: x.Key
}
}))
if (res.IsTruncated) {
res = await s3.listObjectsV2({ Bucket: leBucket, Prefix: prefix, ContinuationToken: cToken }).promise()
} else {
continueWhile = false
}
}
console.log(`found ${keys.length} keys`)
let pa = []
let batchSizes = 10
let chunks = keys.length/batchSizes
let keyBatches = new Array(Math.floor(chunks)+((chunks%1)?1:0))
console.log(`pushing ${keyBatches.length} batches`)
keys.forEach( (x,i) => {
let bIndex = i % keyBatches.length
keyBatches[bIndex] = Array.isArray(keyBatches[bIndex]) ? keyBatches[bIndex] : []
keyBatches[bIndex].push({
Id: `key-${bIndex}-${i}`,
MessageBody: JSON.stringify(x),
MessageGroupId: 'processGroup'+Math.random()
})
})
keyBatches.forEach( x=> {
let p = sqs.sendMessageBatch({
Entries: x,
QueueUrl: leq
}).promise()
.then((response) => {
return response;
})
pa.push( p )
})
await Promise.all(pa)
console.log('done')
return { numKeys: keys.length, numBatches: keyBatches.length }
}
Once startBatch collects all the keys from the 1k chunks listObjectsV2 collects,
it preps an array of arrays mod sorts the keys into batches of 10 (the max of sendMessageBatch).
Then it is all promises to send the message batches asap, so the real fun can start.
Queue peeker
To make the Step function wait for all the lambs to finish, so that it at least floats around till the queue is empty.
exports.checkBatch = (event) => {
console.log('checking',event)
let params = {
QueueUrl: process.env.QUEUE_URL,
AttributeNames: [ 'ApproximateNumberOfMessages' ],
}
return sqs.getQueueAttributes(params).promise()
.then((response) => {
console.log(response)
return response;
})
}
A lamb’s incomplete Turing machine
So the hosed source stream contains appended json objects that has an uglyfied version of this…
{
"messageType": "DATA_MESSAGE",
"owner": "1234567890101",
"logGroup": "vpc-flow-logs",
"logStream": "eni-deadbeef010101-all",
"subscriptionFilters": [
"AccountSetup-VPCSubscriptionFilter-1ABC129120190"
],
"logEvents": [
{
"id": "102010201290192012910291029102912129029102910291090",
"timestamp": 1580515178000,
"message": "2 123456780901 eni-deadbeef101010101 - - - - - - - 1580515178 1580515187 - NODATA"
}
]
}
the only bits I was interested in, was the "timestamp" and the "message" being the spaced out meat contained within that string with this format
"version account-id interface-id srcaddr dstaddr srcport dstport protocol packets bytes start end action log-status"
which needed to be grabbed and slapped with some comma’s where the spaces were so we can csv with the best of the spreadsheet jockeys.
After re-figuring out how the hell node’s streams work, and StackOverflow copy and hack sessions, I came up with this:
const AWS = require('aws-sdk')
const stream = require('stream')
const zlib = require('zlib')
const s3 = new AWS.S3()
const process = require('process')
exports.afunc = async (event) => {
let targetBucket = process.env.S3_BUCKET
let leq = process.env.QUEUE_URL
message = JSON.parse(event.Records[0].body)
console.log(`processing ${JSON.stringify(message)}, ${typeof(message)}`)
const readStream = s3.getObject(message).createReadStream()
let buff = ''
let writtenHeader = false
const re = /"timestamp":([0-9]+),"message":"(.+?)"/g
const transformStream = new stream.Transform({
transform(d,encoding,callback) {
if (!writtenHeader) {
this.push('timestamp,version,account-id,interface-id,srcaddr,dstaddr,srcport,dstport,protocol,packets,bytes,start,end,action,log-status\n')
writtenHeader=true
}
let evalStr = buff+d.toString()
let lastMatch = 0
while ((reresult = re.exec(evalStr))!==null) {
this.push(new Date(Number(reresult[1])).toISOString()+','+reresult[2].replace(/ /g,',')+'\n')
lastMatch=reresult.index+reresult[0].length
}
buff = evalStr.substr(lastMatch)
callback()
}
})
const s3pass = new stream.PassThrough();
const s3promise = s3.upload( {
Bucket: targetBucket,
Key: message.Key+'.gz',
Body: s3pass }).promise()
readStream
.pipe(zlib.createGunzip())
.pipe(transformStream)
.pipe(zlib.createGzip())
.pipe(s3pass)
console.log('s3result',await s3promise);
return message
}
Since SQS does the honours of the message getting and trashing, the lambda does little else but:
- grabs the source stream from the source S3 bucket
- gunzip it
- let a regExing
Transformprocess the Buffer chunks and write out the space-replaced-by-comma stuff it finds in the subsequent buffers - gzip the output
- slings it back to S3 via a
PassThroughstream
The rig
const cdk = require('@aws-cdk/core')
const lambda = require('@aws-cdk/aws-lambda')
const lambdaEventSources = require('@aws-cdk/aws-lambda-event-sources')
const s3 = require('@aws-cdk/aws-s3')
const sfn = require('@aws-cdk/aws-stepfunctions')
const tasks = require('@aws-cdk/aws-stepfunctions-tasks')
const iam = require('@aws-cdk/aws-iam')
const sqs = require('@aws-cdk/aws-sqs')
class FlowLogProcessorStack extends cdk.Stack {
constructor(scope, id, props) {
super(scope, id, props);
const srcBucketName = 'stash-of-hosed-vpc-flow-logs-bucket'
const lebuck = new s3.Bucket(this, 'ResultBucket');
const leq = new sqs.Queue(this, 'processorQ', {
fifo: true,
contentBasedDeduplication: true,
visibilityTimeout: cdk.Duration.seconds(120)
})
const startBatchFunction = new lambda.Function(this, 'startBatchFunction', {
runtime: lambda.Runtime.NODEJS_10_X,
handler: 'jobControl.startBatch',
code: lambda.Code.asset('./handlers/flp'),
timeout: cdk.Duration.seconds(60),
environment: {
S3_BUCKET: srcBucketName,
QUEUE_URL: leq.queueUrl,
},
})
const checkBatchFunction = new lambda.Function(this, 'checkBatchFunction', {
runtime: lambda.Runtime.NODEJS_10_X,
handler: 'jobControl.checkBatch',
code: lambda.Code.asset('./handlers/flp'),
timeout: cdk.Duration.seconds(30),
environment: {
S3_BUCKET: srcBucketName,
QUEUE_URL: leq.queueUrl,
},
})
const processFunction = new lambda.Function(this, 'processorFunction', {
runtime: lambda.Runtime.NODEJS_10_X,
handler: 'processor.afunc',
code: lambda.Code.asset('./handlers/flp'),
timeout: cdk.Duration.seconds(30),
environment: {
S3_BUCKET: lebuck.bucketName,
QUEUE_URL: leq.queueUrl,
},
memorySize: 1024,
})
processFunction.addEventSource(
new lambdaEventSources.SqsEventSource(
leq, { batchSize: 1 }
))
const polStatement = new iam.PolicyStatement({
resources: [
'arn:aws:s3:::'+srcBucketName,
'arn:aws:s3:::'+srcBucketName+'/*',
],
actions: [
"s3:Get*",
"s3:List*",
],
})
startBatchFunction.addToRolePolicy(polStatement)
processFunction.addToRolePolicy(polStatement)
lebuck.grantWrite(processFunction)
leq.grantPurge(startBatchFunction);
leq.grantSendMessages(startBatchFunction);
leq.grantConsumeMessages(checkBatchFunction);
leq.grantConsumeMessages(processFunction);
const startTask = new sfn.Task(this, 'startBatch', {
task: new tasks.InvokeFunction(startBatchFunction),
})
const checkTask = new sfn.Task(this, 'checkBatch', {
task: new tasks.InvokeFunction(checkBatchFunction),
})
const wait = new sfn.Wait(this, 'sleep', {
time: sfn.WaitTime.duration(cdk.Duration.seconds(5)),
})
const loop = new sfn.Pass(this,'loop!')
const done = new sfn.Pass(this,'done!')
const sfndef = startTask
.next(loop)
.next(wait)
.next(checkTask)
.next( new sfn.Choice(this, 'Job Complete?')
.when( sfn.Condition.stringEquals('$.Attributes.ApproximateNumberOfMessages', '0'), done)
.otherwise(loop))
const leSfn = new sfn.StateMachine(this, 'FlowLogProcessorStateMachine', {
definition: sfndef,
timeout: cdk.Duration.minutes(30),
})
}
}
module.exports = { FlowLogProcessorStack }
Pretty much the same stack as I used probing accounts, apart from the parallel bits keeping tabs on the lambda invocations.
This time a Wait (sleep) just slows things down a bit.

PS
-
I tried the new Map step, but realized (after I implemented it like a dumbass) I forgot to - RTFL (Read The Frigging Limits) … 32k in this case being the max data you can pass around between states of an sfn
-
To make Athena’s job a little easier, also looked at parquet-ting (????) the format, but decided it was feature creep after my inner scrum master put a pink sticky note in my minds eye that read: “FOCUS.ON.THE.BURN.(DOWN)!”
-
Glue jobs did cross my mind to ETL like a python bright spark, but I was a little time constrained and hacking is what I do and streams are in js are pretty efficient.
-
If I ever wanted to realtime process this rig - S3 events tickling the RE lambda will be a one super simple change.