Solutionary Evolution
2020-12-25
if a Solutionary [suh-LOO-shuh ner-ee] is
- Noun - a person who identifies inhumane, unsustainable, and unjust systems and then develops healthy and equitable solutions for people, animals, and the environment.
- Adjective - pertaining to or characterized by solving problems in a strategic, systemic way that does the most good and least harm to people, animals, and the environment.
then this post is me not doing any more harm to my future self than I have to.
zie Problem
So I had a problem
- read something
- break it into bits
- make a stash somewhere
- append it to all the previous bits for the day
simple problem?
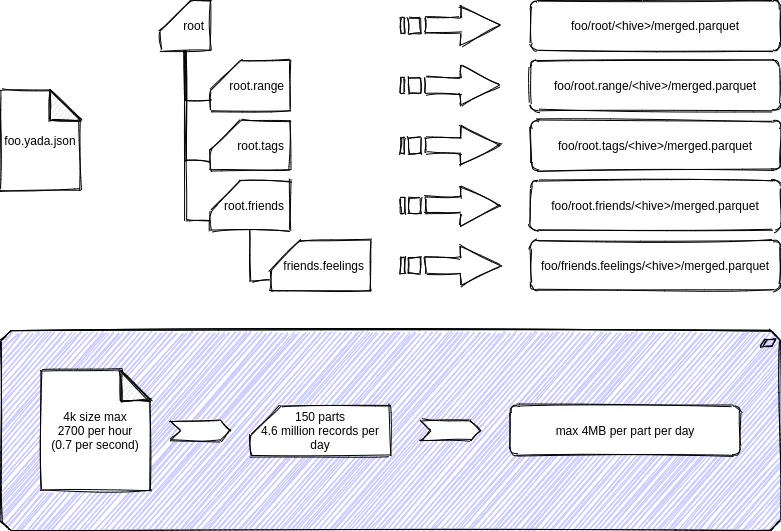
tl;dr here’s what is running in prod
le Toys
The usual serverless suspects were roped in… s3, lambda, dynamodeeb, sqs, all seedy kay’ed up in a git repo.
Since kinesis streams were foreign to me, and me looking at the pricing page and assuming it could not deal with streams dealing with hundreds of types, it led me to give it a wide berth. Reason being I don’t want to deal with knowing what is inside the parts I process until I have to - when I inner join the shit out of them in Athena.
Sounds like a simple four service party right? But holy hell just those had me running around chasing my tail for more than a month.
da Process
This was not something predictable, done before, that one can twerk by shaking instance sizes or storage types up and down, so I took the WellAF genpop principle of “Automate to make architectural experimentation easier” to heart and started with another cdk init --javascript
#1 respond on create, stash in s3, append periodically
Simple - take it, split it into parts, dump it to s3, then later fetch and merge.
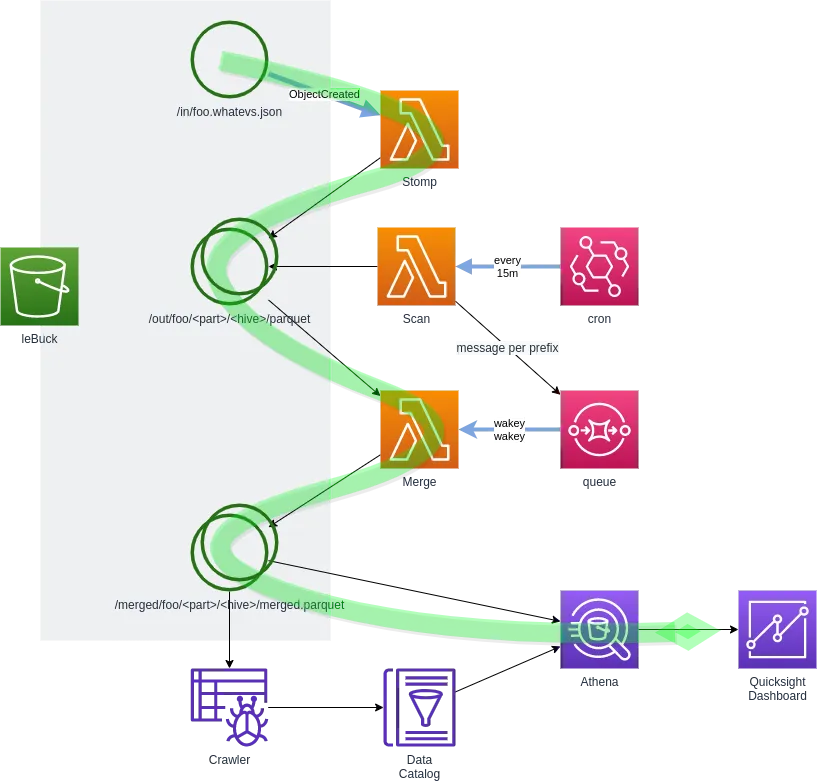
Seeing that the s3 costs went ape shit with all the little ‘in the middle’ PUTS I did of the little parts of the json files prompted me to make a change which lead me to introduce Dynamodb. Mistake.
#2 respond on create, stash in dynamodb, append more frequently
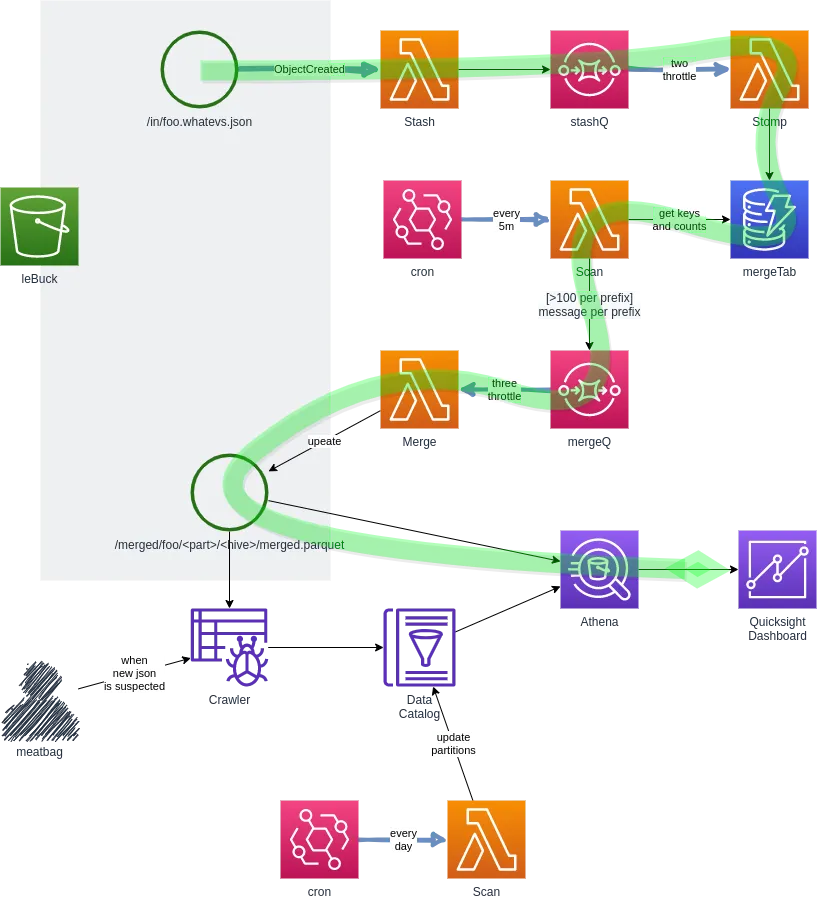
Dynamodb was great - I dumped the parts into a single table and startsWith’ed the secondary index - but letting the part lambda feed loose on an auto-scaling table blew the budget out of the water. So next strategy was ‘lock in the capacities’ and to get that working I tried throttling it with sqs.
I did that first on a single mergeQ but inside that one prefix’s processing was too many writes and needed to go deeper down the throttling rabbit hole.
#3 respond on create, stash in dynamodb, throttle the crap out of dynamo everything to keep the write capacity unit low, append more frequently
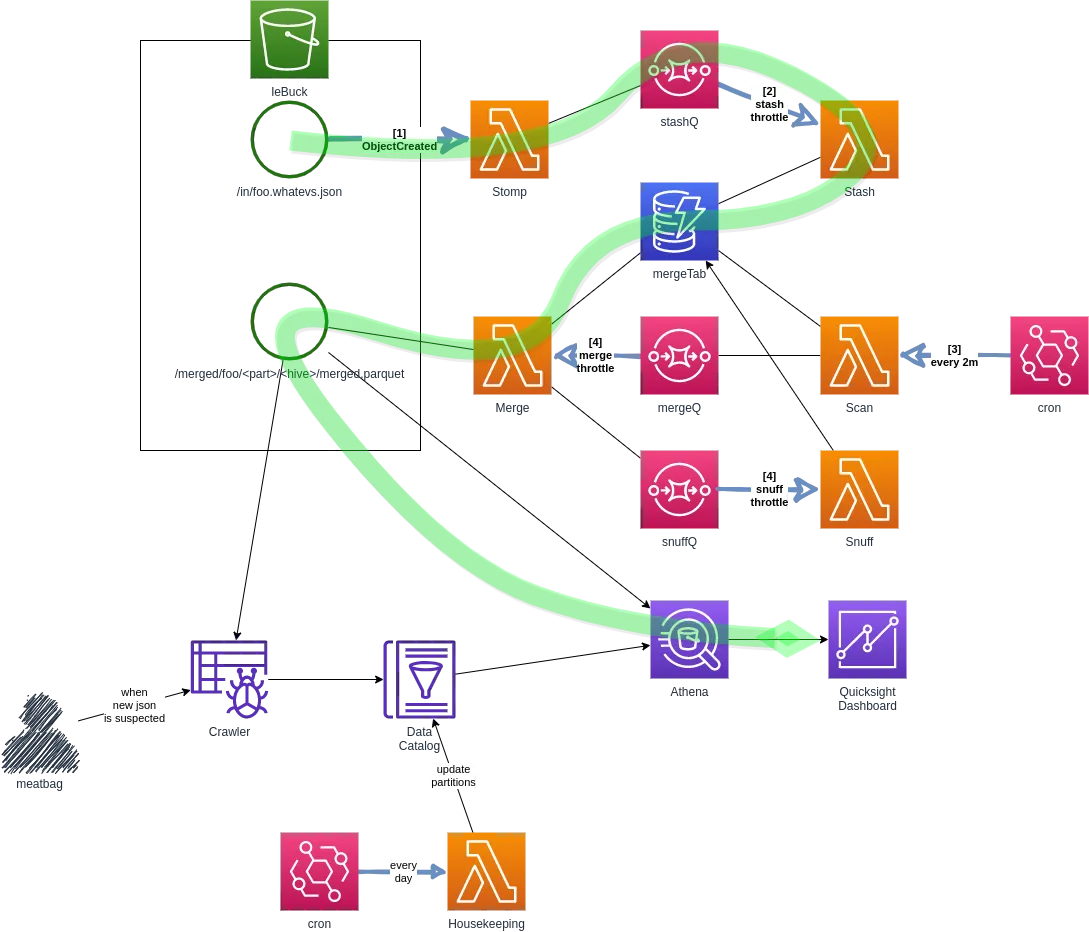
I throttled everything going into and out of dynamo. Now, I sat with so many lambda invocations that it started to overtake dynamo as the fat cat in Cost Explorer. This was the moment when I had so many knobs to turn, I started thinking I really did belong in management.
Back to the drawing board then…
#4 DON’T respond on create, DON’T stash anywhere, make micro batch babies and be merry
So after I just could not keep the WCU’s and lambda costs down to a cheap as dirt level with #3, I considered going to run fargate ecs jobs just since this serverless gig is turning into a freakshow of complexity and cost.
So then it dawned on me - reacting to events is frigging pointless when I only need to consume the findings daily. I can quite easily clump the processing together in memory as long as I only process 1 batch of a bunch of files at a time. If you don’t, the merging will happen in 2 or more concurrent lambda’s memory bits, and shit will hit the ‘lossy’ fan.
So this gets us to the current design, way more straightforward to grok and fondle.
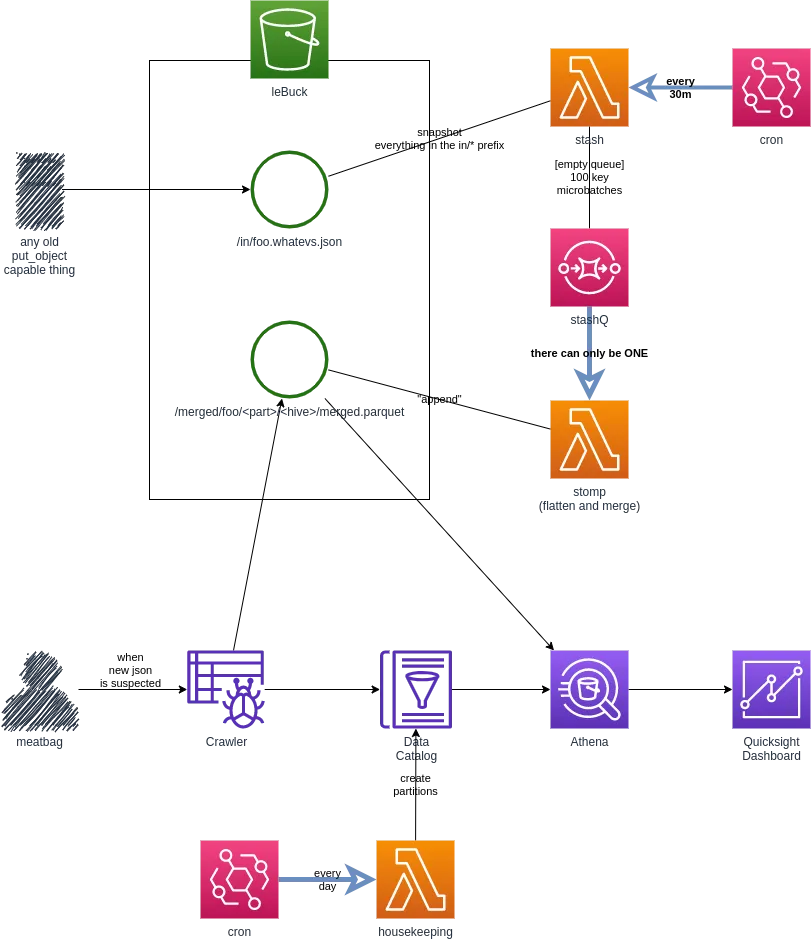
holy Moneybags!
This was never going to break the bank - but for our (used to be) $150 account the previous solutions caused a monster bump to around $600+. I can just hear the corporate bozo’s ringing in my ears… “What?! For a reporting solution? Whyeeee-a! They can make their own frigging reports!”
Here you can see the difference in the per hour charge bits.
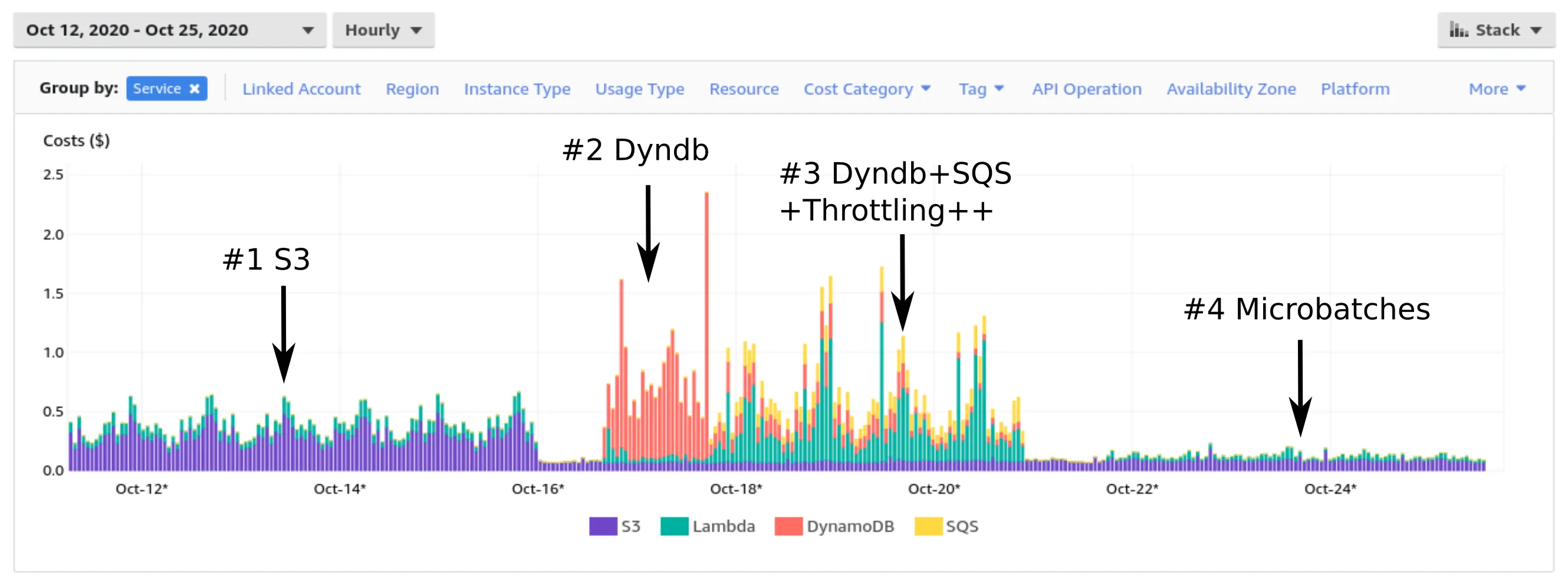
You can see the scale of the extra Tier 1 requests in the first part (#1), and introducing Dynamo and letting its WCU’s autoscale (#2) and then trying to throttle the WCU’s by introducing more and more sqs and lambda (#3) and trying to keep it under control. And finally, the current solution (#4) costs is basically lambda and a little s3 (and mostly due to the parquet files increase in size as the day progresses).
mm Anyhoos
Here are some interesting things I came to realize in my struggles
- You are never done
- Batching isn’t a bad thing if you can squeeze it into a time window that makes sense
- Fit the solution to the problem - not beyond (aka if you don’t need it ‘realtime’ don’t make it ‘realtime’ for no reason)
- When shit gets too complicated to explain via a rigorous session of air drawing, it probably is no good