Silence of the lambs meets the gogo duck
2025-01-17
Chef one: “I have this duck…”
Chef two: “I have this lamb…”
Hacker: “I am shoving that duck inside the lamb, dump it on a bed of golang potatos and make du-lamb-a-tato”
So I’ve recently discovered that the goddess of wisdom aint the only thing awesome at slicing and dicing data. Duckdb ( and VisiData ) are frigging amazing for sql hackers and excel abstainers like me.
Some context
Still planning to take over the world without a server, I recently had the need to put one of my data models & apps into production, so I did the following…
For some context, the application (in this case is an ri purchasing app), which gathers rds instance and reservation info across accounts, shoves it in a bucket (red), does the processing with an sql the recipe [this post] (blue), and spends money (green).
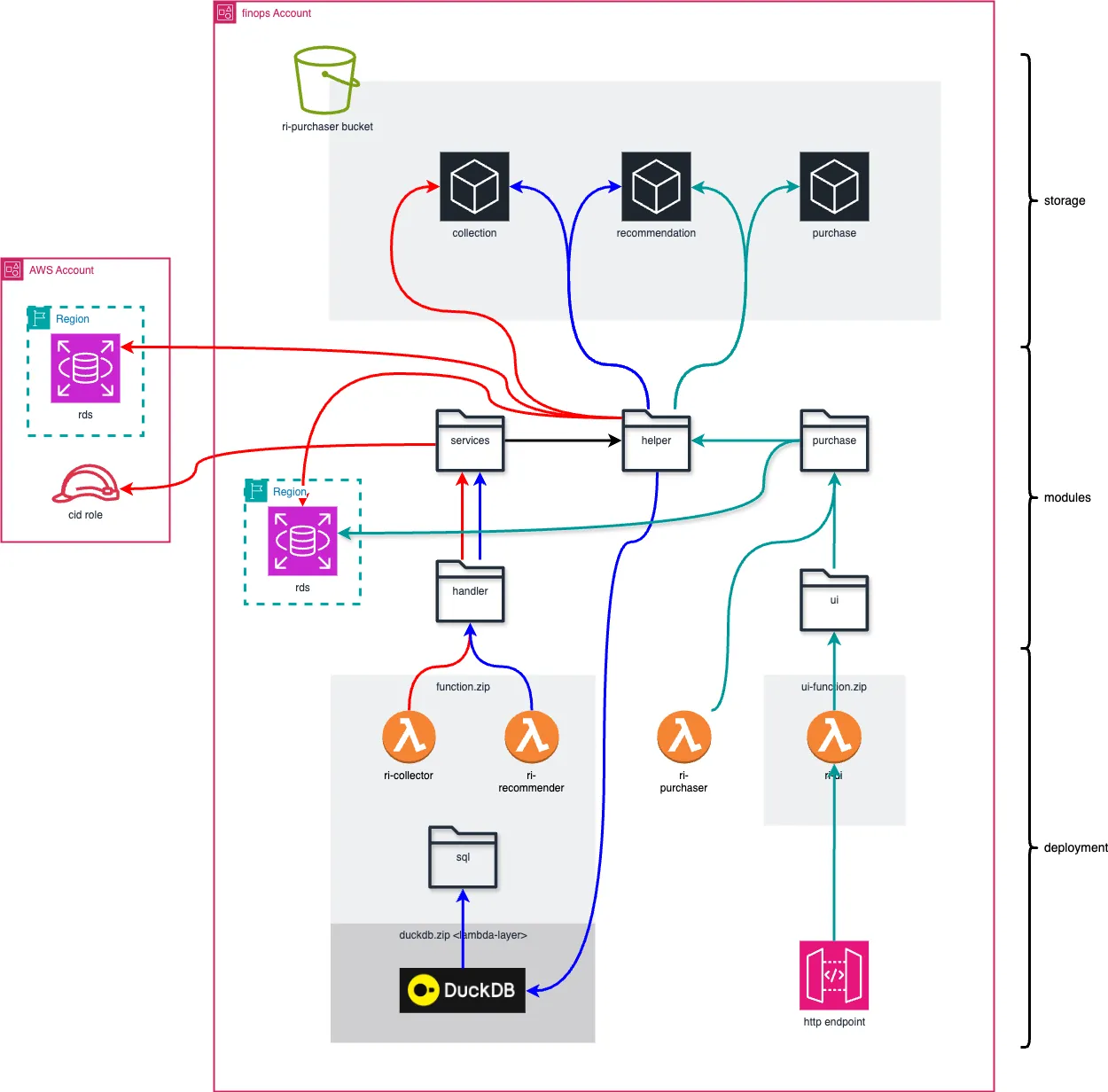
The recipe…
The basic idea is to develop sql with a whole bunch of local iterations of
duckdb -c '.read sql/duckdb/process.sql' | vd
(because I loathe duckdb’s repl, and love vd’s ability to slice and dice json).
Once that solidifies a tad, wrap it in a lambda, put it on top of a lambda layer containing the duckdb binary, and let golang be the goo tying it all together.
Pot a toes
Omitting the paging rds api collectors and the ui serving lambda (similar to this python rig) for brevity…
In order to wrap a duck in a lambda, I use this trio of little hipster funks - relying on the fact that the lambda layer has /opt/duckdb ready for action
and the function’s zip include the sql suace (constraints put on normalized recommendations of what to buy next).
// Fetch the rds and ri inventories from athena/s3 and import them to duckdb
func (s *RiRecommenderService) FetchInventories(ctx context.Context) error {
// Download latest RI list
date := time.Now()
datePrefixPart := fmt.Sprintf("%d/%02d/%02d", date.Year(), date.Month(), date.Day())
err := helpers.DownloadS3File(ctx, s.s3Client, constants.BucketName, constants.CollectorPrefix+"/ri-offering/"+datePrefixPart+"/ri-offering-list.json", "/tmp/ri/ri-offering-list.json")
if err != nil {
slog.Error("Failed to download RI Offering list", "error", err)
return err
}
err = helpers.DownloadS3File(ctx, s.s3Client, constants.BucketName, constants.CollectorPrefix+"/ri/"+datePrefixPart+"/ri-list.json", "/tmp/ri/ri-list.json")
if err != nil {
slog.Error("Failed to download RI list", "error", err)
return err
}
err = helpers.DownloadS3File(ctx, s.s3Client, constants.BucketName, constants.CollectorPrefix+"/ri-cloud-prod/cloud-prod-ri-list.json", "/tmp/ri/cloud-prod-ri-list.json")
if err != nil {
slog.Error("Failed to download static RI list", "error", err)
return err
}
err = helpers.DownloadS3File(ctx, s.s3Client, constants.BucketName, constants.CollectorPrefix+"/rds/"+datePrefixPart+"/rds-list.json", "/tmp/rds/rds-list.json")
if err != nil {
slog.Error("rds download failure", "error", err)
return err
}
err = helpers.DownloadS3File(ctx, s.s3Client, constants.BucketName, constants.CollectorPrefix+"/account-region-cluster.json", "/tmp/rds/account-region-cluster.json")
if err != nil {
slog.Error("rds arc download failure", "error", err)
return err
}
return nil
}
// Create the plan in duckdb extract and put it in s3
func (s *RiRecommenderService) CreatePlan(ctx context.Context) error {
// Process with DuckDB
cmdPrefix := ""
if s.isLambda {
cmdPrefix = "/opt/"
}
if err := os.MkdirAll("/tmp/recommender-output", 0755); err != nil {
return fmt.Errorf("failed to create directory for %s: %w", "/tmp/recommender-output", err)
}
stdout, stderr, rcode, err := helpers.BashIt(cmdPrefix + "duckdb -c '.read sql/duckdb/process.sql'")
if err != nil {
slog.Error("DuckFailure", "error", err)
return err
}
// upload the results to the recommendation bits
date := time.Now()
for _, f := range []string{
"active-ris.csv",
"rds_instance_count.csv",
"ri_coverage.csv",
"ri_bucket.csv",
} {
s3Key := fmt.Sprintf("%s/%s/%d/%02d/%02d/%s", constants.RecommenderPrefix, "csv", date.Year(), date.Month(), date.Day(), f)
err = helpers.UploadFileToS3(ctx, s.s3Client, "/tmp/recommender-output/"+f, constants.BucketName, s3Key)
if err != nil {
slog.Error("upload failure", "error", err)
return err
}
}
for _, f := range []string{
"active-ris.json",
"rds_instance_count.json",
"ri_coverage.json",
"ri_bucket.json",
} {
fname := strings.Split(f, ".")[0]
s3Key := fmt.Sprintf("%s/%s/%d/%02d/%02d/%s", constants.RecommenderPrefix, fname, date.Year(), date.Month(), date.Day(), f)
err = helpers.UploadFileToS3(ctx, s.s3Client, "/tmp/recommender-output/"+f, constants.BucketName, s3Key)
if err != nil {
slog.Error("upload failure", "error", err)
return err
}
}
return nil
}
// ProcessReservedInstances handles the main business logic
func (s *RiRecommenderService) Process(ctx context.Context, omitList []string) error {
if err := s.FetchInventories(ctx); err != nil {
return err
}
if err := s.CreatePlan(ctx); err != nil {
return err
}
return nil
}
Calling Dr Dishs hell
To get the thing running in aws I build it with…
#!/bin/bash
set -e
# Build configuration
HANDLER="bootstrap"
UI_HANDLER="bootstrap"
BUILD_DIR="dist"
ZIP_FILE="function.zip"
UI_ZIP_FILE="ui-function.zip"
# Clean
rm -rf ${BUILD_DIR}
mkdir -p ${BUILD_DIR}
# Build the Go binaries
podman run -it -v `pwd`:/build --rm --platform linux/arm64 public.ecr.aws/docker/library/golang:1.23 /bin/bash -c "/build/scripts/go-build.sh"
# Create zip files
cd ${BUILD_DIR}
zip ${ZIP_FILE} ${HANDLER}
cd ui
zip ../${UI_ZIP_FILE} ${UI_HANDLER}
cd ..
# Download and add DuckDB
curl -L https://github.com/duckdb/duckdb/releases/download/v1.1.3/duckdb_cli-linux-aarch64.zip -o duckdb.zip
# Add duckdb and sql folders
cd ..
zip -r ${BUILD_DIR}/${ZIP_FILE} sql/
Taffy time
…and deploy it with…
#!/bin/bash
set -e
export AWS_REGION=eu-central-1
cd terraform && terraform init && terraform apply -auto-approve
resource "aws_lambda_layer_version" "duckdb" {
filename = "../dist/duckdb.zip"
source_code_hash = filebase64sha256("../dist/duckdb.zip")
layer_name = "duckdb_layer"
compatible_runtimes = ["provided.al2023"]
compatible_architectures = ["arm64"]
}
nothing special in the lambda itself (omitting all the roly polies).
resource "aws_lambda_function" "ri_recommender" {
filename = "../dist/function.zip"
source_code_hash = filebase64sha256("../dist/function.zip")
function_name = "ri_recommender"
role = aws_iam_role.lambda_role_recommender.arn
handler = "main"
runtime = "provided.al2023"
architectures = ["arm64"]
timeout = 300
memory_size = 4096
layers = [aws_lambda_layer_version.duckdb.arn]
environment {
variables = {
DO_PURCHASE = "false"
HANDLER_TYPE = "recommender"
}
}
}
# EventBridge schedule for recommender - runs at 3:30 AM UTC daily
resource "aws_cloudwatch_event_rule" "recommender_schedule" {
name = "ri-recommender-daily-schedule"
description = "Triggers the RI recommender lambda daily at 3:30 AM UTC"
schedule_expression = "cron(30 3 * * ? *)"
}
resource "aws_cloudwatch_event_target" "recommender_target" {
rule = aws_cloudwatch_event_rule.recommender_schedule.name
target_id = "RIRecommenderLambda"
arn = aws_lambda_function.ri_recommender.arn
}
resource "aws_lambda_permission" "allow_eventbridge_recommender" {
statement_id = "AllowEventBridgeInvokeRecommender"
action = "lambda:InvokeFunction"
function_name = aws_lambda_function.ri_recommender.function_name
principal = "events.amazonaws.com"
source_arn = aws_cloudwatch_event_rule.recommender_schedule.arn
}
The customer
The finops folks thought it was awesome and donated a million and a bit towards the rds team, so that was nice (you know - for the billionaire boy space race).
But more importantly it feels quite empowering to not have to do all your processing in athena, py or golang and finding another thing I can shove inside lambdas is fun.
As for cost this rig is next to nothing, way-way inside lambda’s default limits - runs for around 3s (mostly s3), processing around 65MB of inventory and uploading the outputs to s3 again.